公司新闻
公司新闻

作为一家计算芯片企业,进迭时空对RISC-V架构的计算核进行架构创新,不断挖掘其在计算中的潜力。面向未来的大模型(LLM)、AIGC等智能化浪潮,通过RISC- V的DSA设计与软硬一体优化,为未来提供高效、易用的算力。
传统CPU核擅长做控制,传统的CPU或者SoC通过堆叠 CPU核的方式提升算力。这种方式在面向以AI、视觉处理、XR等为代表的下一代计算场景时,计算能力和能效并不是最优的。DSA(DomainSpecific Architecture)作为当下应对特定领域算力需求的有效解决方法,核心理念是面向特定计算场景做体系结构的设计与优化,DSA将成为未来10年计算机体系结构的主流发展方向之一。Google(TPU),NVIDIA(GPU/GPGPU),华为(NPU)等绝大部分国内外知名公司的产品均采用了DSA的计算理念。
纵观计算机发展史,过去四十年经历了X86的Personal Compter和ARM的Mobile Computer两个时代,下一个计算时代可能是泛机器人形态的Robot Computer时代。相较于Personal Compter和Mobile Computer,Robot Computer将变得更主动、更智能,人与计算机的交互方式也将完全不同,这都对底层的计算芯片架构与指令架构提出了不一样的要求。在泛机器人形态的Robot Computer时代,万物都将呈现广义机器人的形态,包括视觉语音等多模态输入、智能计算、Slam相关的空间计算等,算力多样性是下一个计算时代的特点之一。
进迭时空通过对RISC-V 计算核的DSA架构设计与优化,实现在AI、机器视觉、SLAM非线性优化等方面较传统CPU核倍数级的计算能力(或计算能效)提升。应用将驱动芯片设计。未来芯片设计的思路可以简单总结为:分配晶体管数量到通用算力还是DSA算力是一种权衡。最后,多少晶体管用于通用算力,多少晶体管用于DSA算力,不同的应用场景,不同的芯片定位,都会不一样。
深入到DSA内部,会存在不同的算力类型,想要设计好DSA,就需要组织好这些算力。以AI为例,其算力按专有程度从低到高,可以简单分成三个层次:
1.标量算力,主要用于逻辑控制
2.向量算力,主要用于激活、池化、排序等计算
3.矩阵算力,主要是矩阵乘法,用于卷积,全连接等计算
随着算力专有程度的提高,其算力通用性也会降低,算力的可编程性变差。打个比方,我们分别把矩阵算力、向量算力和标量算力,类比作飞机,高铁和汽车三种交通工具。飞机,速度最快,但乘坐成本最高,且只能往来于特定的几个机场站点;高铁,速度相对较快,准备工作相对较少,高铁站的数量也相对较多;汽车,速度相较最慢,但是便捷性最高,也不需要额外的准备工作。
回到算力,标量算力是最通用的算力,可以从功能上覆盖向量计算和矩阵计算,且理论上可以覆盖几乎所有的计算需求;同理,向量计算也可以覆盖矩阵计算的功能;最后,矩阵计算,其算力专有程度最高,只能用于矩阵计算。但是随着算力专有程度变高,越容易堆叠算力,算力的能效比也越高。由于矩阵算力的可编程性较差,需要借助算子库或者DSL(Domain Specific Language)才能把矩阵算力很好的利用起来。
前面提到的TPU/NPU、GPGPU和CPU中都存在这三个级别的算力。其中矩阵算力是为了保证AI算法高效的执行,如TPU、NPU和CPU中的MXU(Matrix Multiplier Unit ),GPGPU中的Tensor core;而向量算力用于保证DSA的可编程性和兼容性,如TPU、NPU和中的Vector Unit,GPGPU中的CUDA core;标量算力则主要用于逻辑控制。
但是从一开始,TPU/NPU、CPU和GPGPU有着不同的起点。
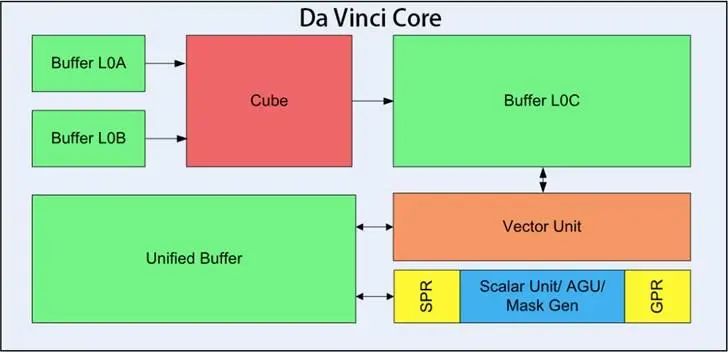
TPU和NPU是从ASIC出发的,解决了AI算法中最核心的计算,拥有非常好的能效比和性能,但是可编程性和兼容性较差。如TPU在第一代和第二代之间,最大的改动就是去掉了pooling等单元,增加了vector单元和scalar单元,提升了TPU的可编程性和兼容性,如上图所示。华为著名的达芬奇架构,就是由这三个算力级别组成,如下图中的,Cube,Vector unit和Scalar unit。而且,现在新的NPU甚至会做一个小的MCU来充当控制单元,现在的NPU可以说越做越像CPU了。

CPU是一个标量处理器,从多媒体需求爆棚的时代开始,以Intel为首的X86阵营就加入了SIMD扩展,其寄存器长度更是从64位扩展到了现在的512位。为了应对AI算力不足的问题,Intel和ARM也是相继推出了自己的矩阵扩展指令,在CPU中扩展了矩阵算力。
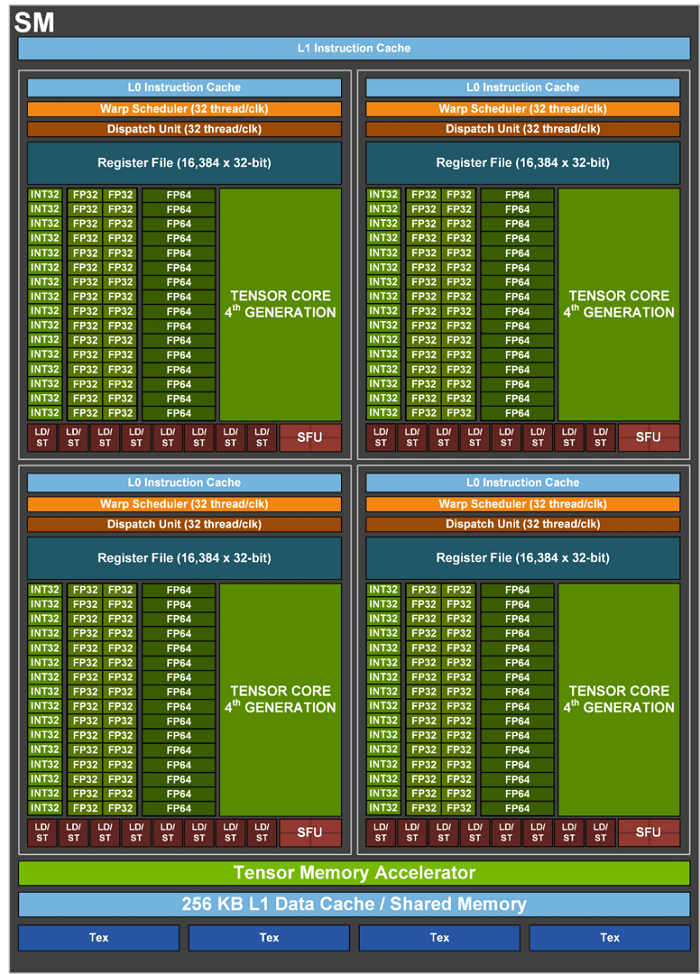
GPGPU是从GPU演化而来,本身就是一个向量处理器(CUDA core)。英伟达去除了GPU中渲染相关的处理单元,并加入矩阵计算单元 Tensor core,就成了现在AI应用最火热的平台。随着大语言模型的崛起,最近英伟达更是炽手可热地被推上了万亿市值。
从这个角度看,这三个发展思路可以说是殊途同归。进迭时空选择了在RISC-V CPU上高度定制融合算力。在《RISC-V架构下 DSA – AI算力的更多可能性》文章中有详细讲述其原由,有兴趣的读者可以跳转查阅。
下面简单介绍,目前进迭时空的DSA架构设计的思路和流程。
进迭时空主要会用到两个工具:功能模拟器+perf功能,性能模拟器+perf功能。其中,功能模拟器使用的是qemu,它具有良好的软件兼容性,良好的RV生态和便利的开发方式。功能模拟器主要的作用是,结合perf工具,从指令数角度,快速找到计算热点,能快速迭代版本。性能模拟器使用的gem5,它具有较好的RV生态,能供进行cycle级别的仿真。性能模拟器的主要作用是,在RTL实现之前,对相关的DSA进行性能验证和性能优化探索。
简单设计流程如下:
在设计之前,需要达成加速的特定领域及其需要加速的倍数的技术目标。以视觉AI为例,简单说明如下:
1.视觉AI中的特定应用,就是CPU锚定的算力级别下,需要支持的所有网络模型。通常是如ResNet,Yolo等标准模型。
2.通过qemu和进迭时空自己扩展的性能分析工具,得到计算热点和计算特征。当然,视觉AI中的计算热点必定是卷积和访存,计算特征必定是矩阵乘法。
3.基于qemu得到的数据,进行DSA设计。设计相关指令或者协处理器,以达到指令数的要求。
4.基于新定义的指令或者协处理器,优化应用。
5.通过qemu重新统计优化后的指令数,和原始指令数对比判断,是否达到指令数要求。
6.若没有达到,则需要重新对DSA和应用进行迭代优化,直至达到要求。
7.指令数达到要求以后,基于gem5进行微架构的优化,如计算热点中的访存。
8.通过gem5的perf工具,统计cycle数。
9.若cycle数没有达到加速目标,则需继续进行微架构优化,直至满足性能要求。
通过以上步骤,DSA初稿基本设计完毕,后续会和硬件同学一起探讨RTL的落地实现。
前文《进迭时空RISC-V高性能核研发取得重大进展》中提及,进迭时空目前主要在AI,机器视觉,SLAM非线性求解这三个方向,定制CPU融合算力。当时也公布了阶段性成果,目前进迭时空已经有了进一步的成果。
基于Tflite推理框架和XNNPACK算子库,进行 ResNet50 V1单核推理测试。
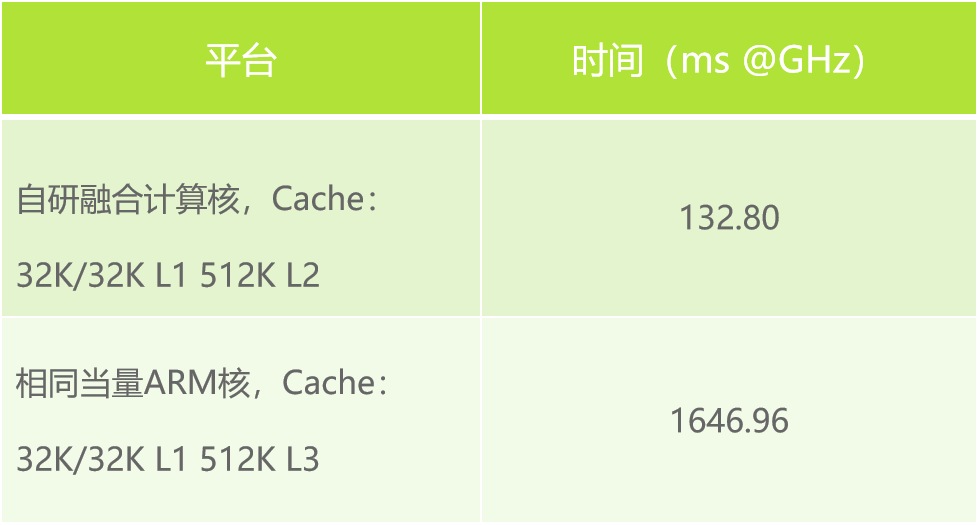
可见,进迭时空自研融合计算核已经达到相同当量ARM核的10倍以上。
基于opencv的图像处理优化结果如下:
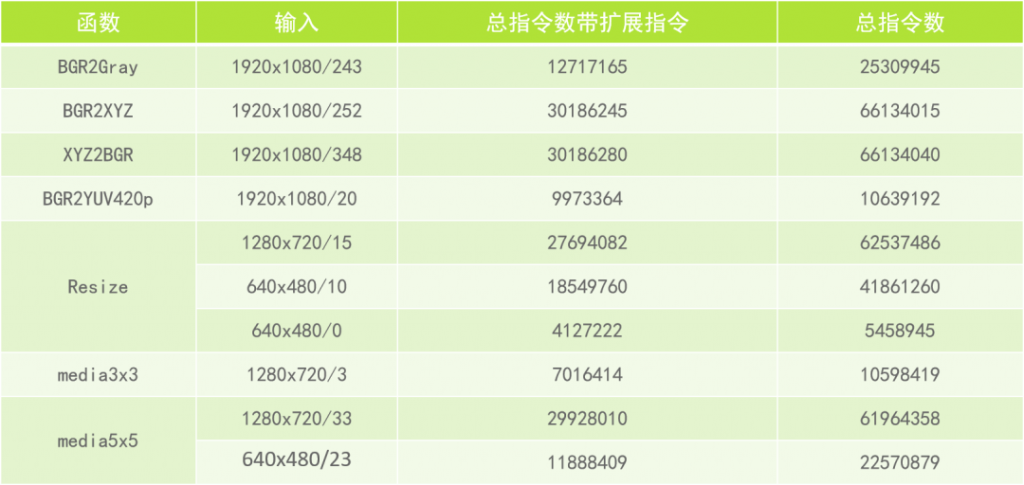
通过扩展少量几条计算类指令,关键算子指令数减少至少在30%,绝大部分都在50%以上。通过FPGA测试,指令数的减少和最后的性能提升非常接近。
后续进迭时空会持续优化CPU融合算力,追求极致,请各位拭目以待。